
Bayes Ahmed
Junior Data Processing Specialist (Traffic Accident),
Dhaka City Corporation, Bangladesh
Email: [email protected]
Introduction and objective
Khulna City is the 3rd largest city and the 2nd port entry of Bangladesh. Other than infrastructure and certain major services, most of the city’s establishments were developed in an unplanned fashion by private initiatives (Master Plan, Khulna City, 2002:4). Although the history of Khulna City extends over more than a century, most of the city’s growth and development has taken place during the recent decades, particularly in post-partition (1947) and post-liberation (1971) periods. In 1991, the population of Khulna City Corporation (KCC) was 6,63,000. A 2007 estimate put the population of KCC area to 1,400,689 (Urban Strategy, Khulna City, 2002:31). The rapid population growth further resulted into unplanned urbanisation, extensive urban poverty, water logging, growth of urban slums and squatters, traffic jams, environmental pollution and other socio-economic problems.
Owing to the process of urbanisation, the physical characteristics of the city are gradually changing as plots and open spaces have been transformed into building areas while low land and water bodies have turned into reclaimed lands. If the present scenario continues then Khulna would soon become an urban slum with the least liveable situation for the city dwellers (Urban Strategy, Khulna City, 2002:42). Therefore, the primary objective of this paper is to forecast the future urban growth of the selected study area within greater Khulna City.
Study area
The proposed study area is the Khulna City Corporation (KCC) and its surrounding impact areas (Figure 1 and Figure 2). Khulna is a linear shaped city, which lies 22049´north latitude and 89034´ east longitude. Its mean elevation is 7 feet above mean sea level. Compared to some of the other cities, Khulna is less prone to natural calamities like floods, cyclones and earthquakes. However, a rise in the sea level may affect Khulna directly (Urban Strategy, Khulna City, 2002:27). The importance of the city lies in a number of strategic factors. First, the city provides important links to the second seaport of the country, namely Mongla Port. Secondly, the city has a strong industrial base. Finally, Khulna is the ultimate source of export processing activities on shrimp cultivation, which is virtually the second biggest foreign exchange earner in Bangladesh, after ready-made garments (Urban Strategy, Khulna City, 2002:25).
Within the KCC core area, there are roughly 11,280 acres of land. Nearly 10 percent of this land is not yet in urban use, which means that about 1100 acres of land is available within KCC for future urban growth (Structure Plan, Khulna City, 2002:59).

Figure 1: Location of Khulna City in Bangladesh.
Source: Banglapedia, National Encyclopedia of Bangladesh, 2011.
Basemap preparation
To prepare the basemaps for analysis purpose and applying the different methods to achieve the research objective, the Landsat satellite images (1989, 1999 and 2009) were collected from the official website of US Geological Survey (USGS). Landsat Path 137 Row 44 covered the whole study area. Map projection of the collected satellite images was universal transverse mercator (UTM) within zone 46 N– datum world geodetic system (WGS) 84 and the pixel size was 30 meters. Five land cover types were identified for this research (Table 1).

Figure 2: Location of the Study Area (Areas of Khulna City Corporation and Adjoining Fringe Areas) on Landsat Satellite Images. Map prepared by the researcher; Image Source: U.S. Geological Survey (USGS), 2010 and Shapefile Source: Khulna City Corporation (KCC), 2008.

Table 1: Details of the Land Cover Types.
For the purpose of ground-truthing/referencing, several basemaps of Khulna City were collected from the Survey of Bangladesh (SoB). Google Earth proved another option to get some ideas about the recent land cover pattern. The detail land use map (2009) of the city was collected from the Khulna City Corporation (KCC).These reference data were used for training site selection and accuracy assessment of the final land cover maps.
To classify the images a ‘Supervised Classification’ method was used (Eastman, 2009). At the beginning, the training sites were developed, which were based-on the collected reference data and ancillary information. After developing signature files for all the land cover types the images were classified using a hard classifier called ‘Fisher Classifier’. Fisher performs linear discrimination analysis (Eastman, 2009). Then a 3×3 mode filter was applied to generalise the fisher classified land cover images. This post-processing operation replaced the isolated pixels to the most common neighbouring class. Finally, the generalised images were reclassified to produce the final version of land cover maps for different years (Figure 3).

Figure 3: Final Land Cover Maps of the Study Area.
Accuracy assessment
The next stage of image classification process was accuracy assessment. For each classified image 250 reference pixels were generated using stratified random distribution process. Then, the collected base maps were used to find the land cover types of the reference points. The overall accuracies for 1989, 1999 and 2009 were found to be 85.89 percent, 87.56 percent and 92.78 percent respectively, with kappa statistics of 0.8021, 0.8398 and 0.8649. It was typical that most land cover classification images were 85 percent accurate (Eastman, 2009). Therefore, it could be stated that the classification accuracy achieved here was above the satisfactory level.
Methods, results and discussion
Stochastic Markov Model
The first model that had been implemented was given the name ‘Stochastic Markov Model (St_Markov)’ because this model combined both the stochastic processes as well Markov chain analysis techniques (Basharin et al, 2004). This kind of predictive land cover change modelling was suitable when the past trend of land cover changing pattern was known (Eastman, 2009). A Markov chain was a stochastic process (based on probabilities) with discrete state space and discrete or continuous parameter space (Balzter, 2000). In this random process, the state of a system s at time (t+1) depends only on the state of the system at time t and not on the previous states. Here, the past and future were independent (Eastman, 2009). At the beginning, Markov chain produced a transition matrix (Table 2), a transition areas matrix (Table 3) and a set of conditional probability images by analysing two qualitative land cover images (Figure 4) from two different dates i.e. 1989 and 1999 (Eastman, 2009).

Table 2: Markov Probability of Changing among Land Cover Types (1989-1999).

Table 3: Cells Expected to Transition to Different Classes (1989-1999).

Figure 4: Markovian Conditional Probability Images (1989-1999).
The matrix of transition probabilities (Table 2) showed the probability that each land cover category would change to other categories in 2009. Table 3 represented the number of cells (30 m × 30 m) that would be transformed over time from one land cover type to other types. Markov Chain Analysis also produced related conditional probability images (Figure 4) with the help of transition probability matrices. Each conditional probability image showed the possibility of transitioning to another land cover class. It was clear that the Markovian conditional probability of being built up area ranged upto 0.32 (Figure 4). It indicated that most areas would convert into built up areas. This probabilistic prediction was dependent upon the past trend of the last ten years (1989-1999).
The next step was to make one map for future prediction aggregating all the Markovian conditional probability images. This prediction was performed by a stochastic choice decision model which created a stochastic land cover map by evaluating and aggregating the conditional probabilities in which each land cover can exist at each pixel location against a rectilinear random distribution of probabilities (Eastman, 2009). Figure 5 shows the Stochastic Markov predicted land cover map of 2009.

Figure 5: St_Markov Predicted Land Cover Map of Khulna City (2009).
Cellular Automata Markov Model
The second model that was implemented was named ‘Cellular Automata Markov Model (CA_Markov)’. CA_Markov combined the concepts of Markov chain, cellular automata (Maerivoet, 2005), multi-criteria evaluation (Malczewski, 2004) and multi-objective land allocation (Eastman, 2009). CA_Markov was useful for modelling the state of several categories of a cell based on a matrix of Markov transition areas; transitional suitability images and a user defined contiguity filter. A Markov model applied contiguity rule, like a pixel near to an urban area, was most likely to be changed into urban area (Eastman, 2009). In this research, a 3×3 mean contiguity filter had been used (Figure 6) for modelling purpose.

Figure 6: The 3 × 3 Mean Contiguity Filter for CA_Markov Modelling.
The next step was to prepare suitability maps for the land cover types. The basic assumption used for preparing suitability images was that “the pixel closer to an existing land cover type has the higher suitability”. It means a pixel completely within vegetation has the highest suitability value (255) and pixels far from existing vegetation pixels would have less suitability values. The farthest pixels from vegetation would show the lowest suitability values. Here, the suitability decreased with distance. Therefore, a simple linear distance decay function was appropriate for this basic assumption. The land cover maps were standardised (Figure 7) to the same continuous suitability scale (0-255) using fuzzy set membership analysis process (Eastman, 2009).
At the end, the Markov transition area matrix (Table 3), all the suitability images (Figure 4), the 3×3 CA contiguity filter (Figure 6) and the base map of Khulna city (1999) were used to predict the land cover map of 2009. The CA_Markov predicted the final land cover image (2009) of Khulna city (in Figure 8).
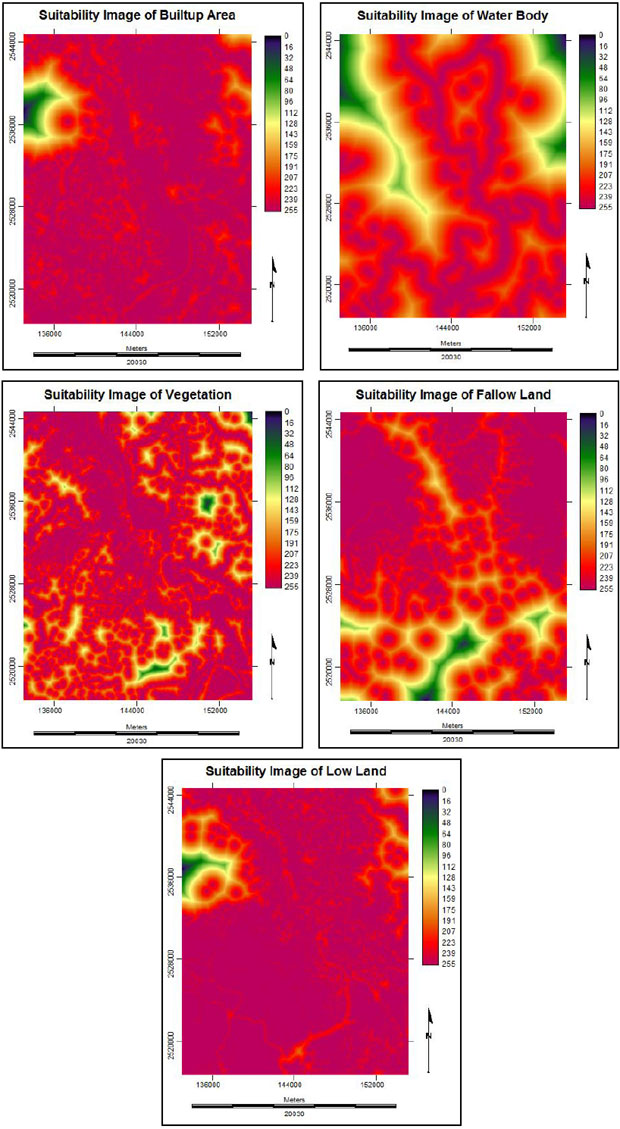
Figure 7: Suitability Images of Each Land Cover Type (1999).
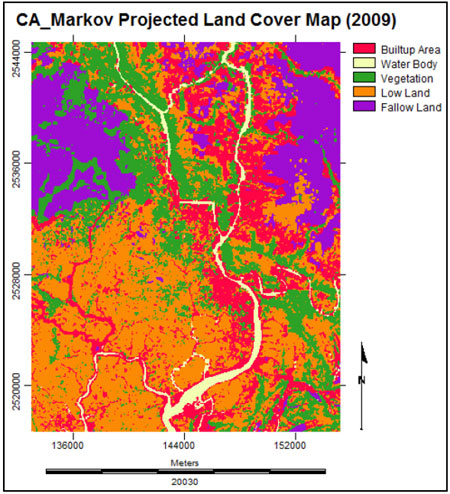
Figure 8: CA_Markov Projected Land Cover Map of Khulna City (2009).
Multi-Layer Perceptron Markov Model
Inspired by human biological nervous system, the third model was named ‘Artificial Neural Network (ANN)’ (Karul and Soyupak, 2006). In a typical ANN model, simple nodes are connected together to form a network of nodes. Some of these nodes are called input nodes; some are output nodes and in between there are hidden nodes (Atkinson and Tatnall, 1997). Multi-layer perceptron (MLP) is a feed-forward neural network with one or more layers between input and output layers. The great advantage of using MLP perceptron neural network is that it gives an opportunity to model several or even all the transitions at once (Eastman, 2009).
The basic concept of modelling with MLP neural network adopted in this research was to consider the change in built up area over the years. In general, it meant that other land cover types were primarily contributing to increase the built up area. At this stage, the issue of which variables affect the change to built up area (1989-1999) was considered. Therefore, only the transitions from ‘water body to built up area’, ‘vegetation to built up area’, ‘low land to built up area’ and ‘fallow land to built up area’ were considered for model simulation. These four transitions were termed as “All” here. Figure 9 exhibits the transition from all to built up area.

Figure 9: Transition from All to Builtup Area (1989-1999).
It was logical that new areas would be converted to built up area where there are existing built up areas. Therefore, six driver variables were selected for MLP_Markov modelling. These included distance from all to built up area, distance from water body, distance from vegetation, distance from low land, distance from fallow land and empirical likelihood image.
The empirical likelihood transformation was an effective means of incorporating categorical variables into the analysis (Figure 10). It was produced by determining the relative frequency of different land cover types occurred within areas of transition (1989 to 1999). The numbers (legend) indicated the likelihood of changing into built up area. The higher the value, the likeliness of the pixel to change into the built up cover type is more.
Now, it was important to test the potential explanatory power of each variable. The quantitative measures of the variables were tested through Cramer’s V (Cramér, 1999). It was suggested that the variables that have a Cramer’s V of about 0.15 or higher were useful while those with values of 0.4 or higher were good (Eastman, 2009).

Figure 10: Empirical Likelihood Image (1989-1999).
After getting satisfactory Cramer’s V values for all the driving variables, now the time was to run MLP neural network model. For each principal transition, particular weights had to be obtained. The MLP running statistics gave a very high accuracy rate of 93.45 percent. The RMS error curve was found smooth and descent after running MLP neural network. Based on these running statistics, the transition potential maps were produced. These maps depicted, for each location, the potential it possessed for each of the modelled transitions (Eastman, 2009).
Using this kind of MLP neural network analysis it was possible to determine the weights of the transitions (1989-1999) that would be included in the matrix of probabilities of Markov chain for future prediction. The transition probabilities are shown in Table 4. Based on all these information from MLP neural network, the final land cover map of 2009 (Figure 11) was simulated through Markov chain analysis. The whole procedure, for predicting the land cover map this way, was termed as ‘MLP_Markov’ model.

Table 4: Transition Probabilities (Neural Network Weights) for Markov Chain.

Figure 11: MLP_Markov Projected Land Cover Map of Khulna City (2009).
Model validation and selection
Model validation refers to comparing the simulated and reference maps. Now, the task was to select the most suitable model. The selection was performed based on the overall kappa statistics (Pontius, 2000). The assumption was that the higher the overall kappa values, the better the model.

Table 5: Overall Kappa Statistics (2009).
After analysing Table 5, it could be concluded that MLP_Markov model was showing the highest values, of different types of kappa coefficients, among the three models. Therefore, the MLP_Markov model was selected for predicting the land cover map of Khulna City for the year of 2019.
Simulating the land cover map of 2019
The base maps of 1999 and 2009 were used to predict the land cover map of 2019 (Figure 12). The procedure followed here was the same as stated in the MLP_Markov modelling (section 4.3).

Figure 12: MLP_Markov Projected Land Cover Map of Khulna City (2019).
Analysis of the final predicted map (2019)
The predicted map of 2019 revealed that 33.33 percent of the total area would be occupied by the ‘built up area’ cover type (Figure 13). On the other hand, ‘fallow land’ and ‘low land’ cover types were going to decrease in a notable way (from 25 percent to 16 percent and 38 percent to 28 percent). Moreover, changes in ‘water body’ and ‘vegetation’ cover types were negligible.

Figure 13: Percentages of Presence of Land Cover Types Over the Years (1989-2019).
Conclusions
Despite all kinds of limitations, it can be concluded that the accuracy results of the supervised classified images, Kappa co-efficient values for model validation and the overall predictive results have been found exceeding the agreeable levels.
Emergence of GIS and RS technology as an efficient tool for detailed survey, mapping, modelling, monitoring and analysis, especially in countries like Bangladesh has paramount importance.
The traditional plan making process, which involves extensive surveying, is expensive and time consuming. This kind of research to forecast the future is not only time and money saving, but also effective. Therefore, there is an urgent need for long term planning and management strategy, in order to make an appropriate use of this technology, for the sustainable development of the country. Awareness among the policy makers, different professionals and academicians needs to be increased for the existence and sustainable use of this modern technology in the present and near future.
Acknowledgments
I would like to thank Dr. Raquib Ahmed, Director, Institute of Environmental Science, Rajshahi University, Bangladesh for his thoughtful suggestions and enduring guidance at different stages of this research. I would also like to express my gratitude to Dr. Pedro Latorre Carmona, Dr. Mário Caetano, Dr. Edzer Pebesma, Dr. Nilanchal Patel and Dr. Filiberto Pla Bañón for their support and comments regarding necessary corrections.
Finally, I would also like to thank the European Commission and Erasmus Mundus Consortium (Universitat Jaume I, Castellón, Spain; Westfälische Wilhelms-Universität, Münster, Germany and Universidade Nova de Lisboa, Portugal) for providing me the funding and other research opportunities.
References
- Atkinson, P. M.; Tatnall, A. R. L. 1997. ‘Introduction neural networks in remote sensing’, International Journal of Remote Sensing, vol. 18: 4, pp. 699-709.
- Balzter, H. 2000. ‘Markov chain models for vegetation dynamics’, Ecological Modelling, vol. 126, pp. 139–154.
- Basharin, G. P.; Langville, A. N.; Naumov, V. A. 2004. ‘The life and work of A. A. Markov’, Linear Algebra and its Applications, vol. 386, pp. 3–26.
- Billah, M; Rahman, G. A. 2004. ‘Land Cover Mapping of Khulna City Applying Remote Sensing Technique’, paper presented in the 12th International Conference on Geoinformatics- Geospatial Information Research: Bridging the Pacific and Atlantic 2004, organized by University of Gävle, Sweden, 7-9 June 2004.
- Cramér, H. 1999. Mathematical Methods of Statistics. USA: Princeton University Press.
- Das, T. 2009. ‘Land Use / Land Cover Change Detection: an Object Oriented Approach, Münster, Germany’, Thesis: Master of Science in Geospatial Technologies, Institute for Geoinformatics, University of Münster, Germany.
- Eastman, J. R. 2009. IDRISI Taiga Guide to GIS and Image Processing (Manual Version 16.02) [Software], Clark Labs: Clark University, Massachusetts, USA.
- Karul, C.; Soyupak, S. A. 2006. ‘Comparison between neural network based and multiple regression models for chlorophyll-a estimation’. In Ecological Informatics, Recknagel, F., Eds.; Springer: Berlin, pp. 309-323.
- Lambin, E.F. 2001. Remote Sensing and GIS Analysis. In International Encyclopedia of the Social and Behavioral Sciences, edited by N.J. Smelser e P.B. Baltes (Oxford: Pergamon), pp. 13150-13155.
- Maerivoet, S.; Moor, B. D. 2005. ‘Cellular automata models of road traffic’, Physics Reports, vol. 419 (1), pp. 1-64.
- Malczewski, J. 2004. ‘GIS-based land-use suitability analysis: a critical overview’, Progress in Planning, vol. 62, pp. 3–65.
- Master Plan. 2002. ‘Structure Plan, Master Plan and Detailed Area Plan (2001-2020) for Khulna City’, Volume III, AQUA-SHELTECH CONSORTIUM, Khulna Development Authority, Ministry of Housing and Public Works, Government of the People?s Republic of Bangladesh.
- Pontius, R. G. 2000. ‘Quantification error versus location error in comparison of categorical maps’, Photogrammetric Engineering & Remote Sensing, vol. 66 (8), pp. 1011-1016.
- Structure Plan. 2002. ‘Structure Plan, Master Plan and Detailed Area Plan (2001-2020) for Khulna City’, Volume II, AQUA-SHELTECH CONSORTIUM, Khulna Development Authority, Ministry of Housing and Public Works, Government of the People?s Republic of Bangladesh.
- Urban Strategy. 2002. ‘Structure Plan, Master Plan and Detailed Area Plan (2001-2020) for Khulna City’, Volume I, AQUA-SHELTECH CONSORTIUM, Khulna Development Authority, Ministry of Housing and Public Works, Government of the People?s Republic of Bangladesh.


